
I have spent the last year using Claude Code every day and shipping production AI pipelines and agentic systems day in and day out, and the gap between *using* an LLM and *understanding* one was starting to show in my work. This book closed that gap - not by drowning me in math, but by building the intuition that actually makes the everyday tools feel less like magic and more like something I can reason about. Below is the honest review of why I think it is the most leverage-per-page book I have read this year, especially if you live inside Claude Code or build agentic workflows for a living.
Hands-On Large Language Models is the O'Reilly book by Jay Alammar - the man behind 'The Illustrated Transformer' that taught most of the industry what a transformer actually is - and Maarten Grootendorst, the author of BERTopic. It is a visually-led, intuition-first tour of the entire language AI stack: tokens, embeddings, the transformer block, classification, clustering, prompt engineering, semantic search and RAG, multimodal models, and finally how these models are trained and fine-tuned. It shipped in late 2024 with O'Reilly, runs roughly 400 pages, and is genuinely one of the most beautifully illustrated technical books I own. If DDIA is the textbook for system design, this is the textbook for what is happening inside the model you are prompting all day.

I have been using Claude Code every day for over a year and shipping production AI pipelines and agentic workflows day in and day out, and I noticed that the gap between people who *use* LLMs and people who *understand* LLMs was starting to show in my own work. I could prompt my way out of most things, but the moment a pipeline broke - a retrieval step returned garbage, a chunking strategy under-performed, a multimodal pipeline matched the wrong image - I was guessing at the cause instead of reasoning about it. I wanted a book that closed that gap without burying me in math. Alammar's reputation from the illustrated blog posts made this an obvious pick: get the intuition first, then earn the math later if I need it.
Jay Alammar is a Director and Engineering Fellow at Cohere and the author of a series of blog posts ('The Illustrated Transformer', 'The Illustrated GPT-2', 'The Illustrated BERT, ELMo, and co.') that have collectively been the on-ramp into modern NLP for an entire generation of engineers. If you have ever seen those clean diagrams of attention heads and embedding lookups making the rounds on Twitter, that is him. Maarten Grootendorst is the author of BERTopic and KeyBERT - hugely popular open-source libraries for topic modeling and keyword extraction - and writes the 'Exploring Language Models' newsletter. Together they bring exactly the right pairing: Alammar's gift for visual explanation and Grootendorst's hands-on toolkit for actually using language models on real data.
The book is split into three parts. Part I - Understanding Language Models - is the conceptual base: a recent history of language AI from bag-of-words to transformers, then the two central building blocks (tokens and embeddings) and finally a deep look inside the transformer architecture itself, essentially an updated, expanded version of Jay's famous 'Illustrated Transformer' blog post. Part II - Using Pretrained Language Models - is the hands-on middle: text classification, clustering and topic modeling, prompt engineering, advanced text generation with chains/memory/agents, semantic search and RAG, and a closing chapter on multimodal models. Part III - Training and Fine-Tuning - covers creating embedding models, fine-tuning representation models for classification, and fine-tuning generative models with techniques like LoRA and DPO. Each chapter is independent enough that you can skip around, which is exactly how I read it.
The book opens by stating its philosophy outright: build intuition first, derive equations later. The pace of the field is brutal - papers obsolete each other in months - so chasing the latest model is a losing game. What does not change is the *shape* of the ideas: a token is a chunk of text the model actually sees, an embedding is a vector that captures meaning, attention is how the model decides which other tokens matter for the current one. Once those shapes are solid you can read any new paper, any new model card, any new framework, and slot it into a mental map. That is the book's real value. Alammar is famous for this style and it shows on every page - illustrations carry the weight, prose explains them, and code at the end shows you how to actually run it on your laptop or in Colab.
If I could only keep one chapter from this book, it would be the one on tokens and embeddings. Tokens are the unit the model actually thinks in - not characters, not words, but subword chunks chosen by a tokenizer like BPE or SentencePiece. Once you have seen the same sentence tokenized by GPT-2 vs LLaMA vs a multilingual model, you understand instantly why prompts behave differently across providers, why some non-English languages cost dramatically more tokens, why typos and weird Unicode can wreck a system, and why 'token efficiency' is a real engineering metric, not a buzzword. Embeddings, then, are the geometry the model uses to reason: every token is a point in a high-dimensional space, and 'meaning' is *direction* and *distance* in that space. Word2vec, the king/queen analogy, contrastive training - this is where it all clicks. After this chapter, the phrase 'vector database' stops being magic and becomes obvious.
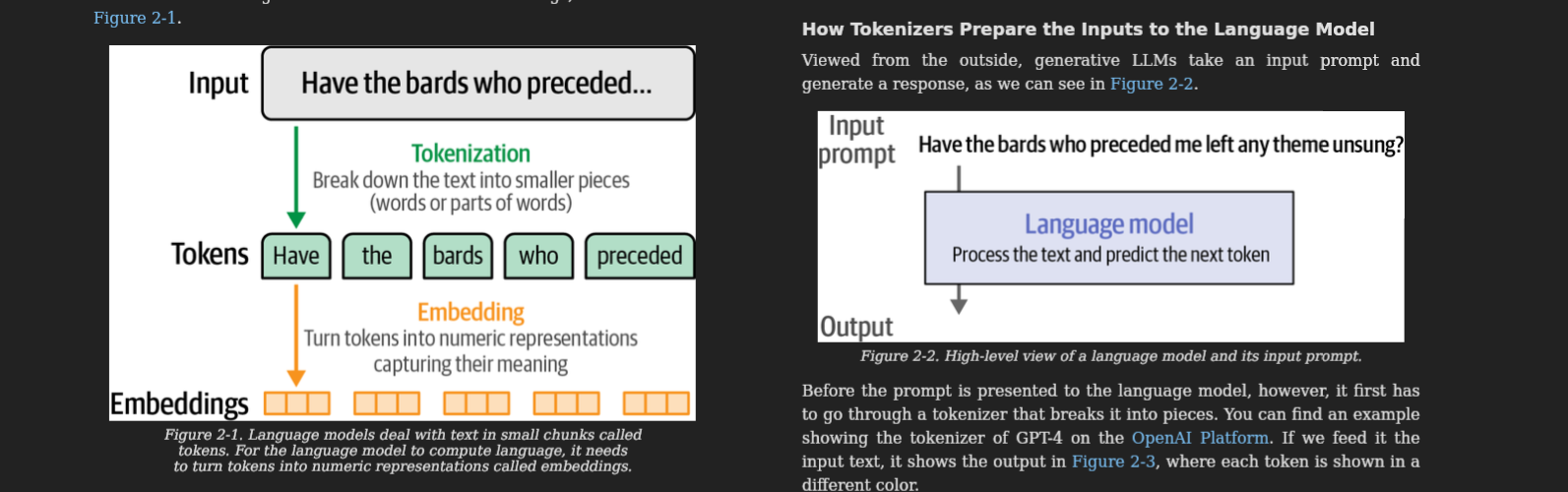
Chapter 3 is the upgraded 'Illustrated Transformer.' It walks the forward pass through a generative LLM end-to-end: tokenizer turns text into IDs, an embedding lookup turns IDs into vectors, a stack of transformer blocks (each one a self-attention layer plus a feed-forward layer) refines those vectors, and a final linear+softmax head converts the last vector back into a probability distribution over the next token. Then the model picks one (greedy, top-k, top-p, temperature - the chapter walks through each), appends it, and runs the whole thing again. The KV cache, parallel processing, RoPE positional embeddings, and recent improvements to attention are all explained with the same visual style. The single most useful realization for me: the model does not 'know' the future, it just predicts one token at a time, and *every* trick we use - chain-of-thought, agents, structured output - is some way of getting it to take more useful steps in that one-token-at-a-time loop.
Half of the book is, in some sense, an extended argument for taking embeddings seriously. Classification with embeddings, clustering with embeddings, topic modeling with embeddings (BERTopic, Maarten's own library), semantic search with embeddings, RAG with embeddings, recommendation systems with embeddings - the same primitive, used six different ways. Once you internalize that an embedding is just 'meaning as coordinates,' a huge amount of AI engineering becomes legible. A semantic search system is: embed your documents, embed the query, return the closest documents by cosine distance. A RAG system is the same thing with an LLM stitched on the end. A clustering pipeline is the same thing with UMAP for dimensionality reduction and HDBSCAN for grouping. The chapter on text clustering and topic modeling builds exactly that pipeline step by step, and it is the cleanest 'this is how a real pipeline is shaped' explanation I have read.
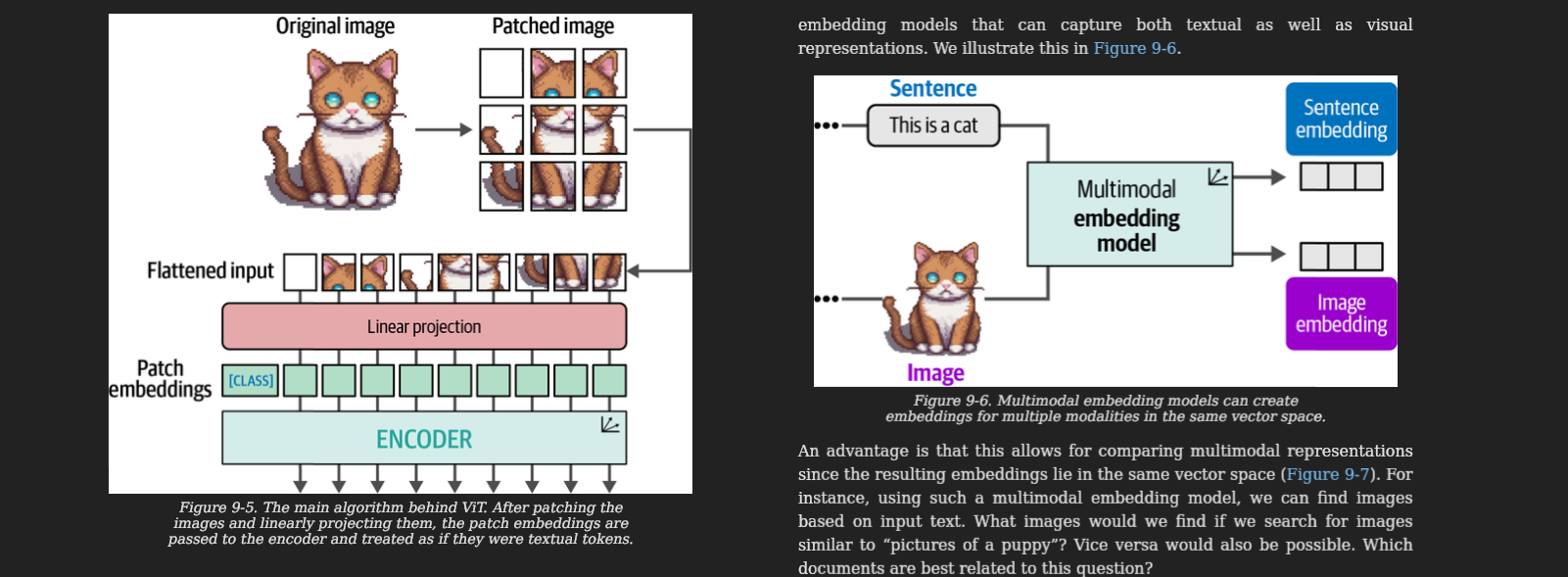
Chapter 9 is the one I keep going back to. It explains how vision transformers work (an image is just a grid of patches, each patch is a token, attention does the rest), then walks through CLIP - the model that, by training on hundreds of millions of (image, caption) pairs with a contrastive loss, ends up with a *single shared embedding space for text and images*. That is the unlock. A photo of a dog and the string 'a dog' can land near each other in the same vector space. Once you have that, image search by text query, text search by image, zero-shot classification on arbitrary categories, and image-grounded chat all become variations on the same idea. The chapter then walks through BLIP-2 and how a frozen vision encoder can be glued to a frozen LLM with a small trainable bridge, which is the recipe most modern multimodal models still riff on. This is the chapter that turned 'multimodal' from a marketing word into a thing I can actually build with.
Chapters 6 and 7 cover prompt engineering and the agentic patterns built on top: in-context learning (showing examples), chain-of-thought (think before you answer), self-consistency (sample multiple answers and vote), tree-of-thought (explore branches), constrained decoding (force the output into a grammar), chains (LangChain-style multi-step pipelines), memory (buffer, windowed, summary), and finally ReAct-style agents that interleave reasoning and tool calls. None of this is novel if you have been using Claude Code or building agentic workflows for a while - but seeing it laid out *after* the chapters on tokens and the transformer block changes the texture of it. Chain-of-thought is not a magic spell, it is more useful tokens to attend to. An agent is not a separate thing, it is a generation loop with tools wired into the decoding step. Once you see it that way, you stop treating prompts as incantations and start designing them like the small programs they actually are.
Claude Code is the most leverage I get out of a single tool, and the better my mental model of what is happening on the other side of the wire, the better the sessions go. Knowing how tokenization works changes how I write prompts - I keep file paths, code, and structured fields together, because the tokenizer respects structure. Knowing about the context window and KV cache changes how I structure long sessions - I front-load the stable context (CLAUDE.md, project files) and let the volatile stuff stream at the end, so the cache stays warm. Knowing that the model picks one token at a time changes how I phrase requests - I ask for the plan first, then the code, because the plan tokens condition the code tokens. Knowing how embeddings and retrieval work changes how I architect the codebase itself - I keep modules cohesive and well-named, because that is what makes any retrieval-based assistant (and Claude Code's own search) actually find the right thing. None of this is in the Claude Code docs - it is in the model itself, and this book is the closest thing to a manual for that.
Most AI pipelines I have seen in the wild are some combination of: embed something, store it in a vector DB, retrieve it later, stitch it into a prompt, optionally call a tool, parse the response. Every single one of those steps is a chapter in this book. When a RAG pipeline returns the wrong context, the bug is almost always upstream - bad chunking, wrong embedding model, no reranker, dimension mismatch, normalization missing - and you cannot debug what you do not understand. When an agent starts looping, the answer is rarely 'add more prompt' - it is usually 'shorten the loop, structure the tool output, give it less and clearer choices.' When a multimodal feature ships and quietly mismatches images, it is almost always because text and images are being embedded by different models that do not share a space. The book gives you the vocabulary to *name* these failure modes, which is the first step to fixing them. After reading it, my own pipelines got smaller, not bigger - because I stopped adding heuristics on top of misunderstood primitives and started picking the right primitive in the first place.
This is the most beautifully illustrated technical book I own, full stop. There are over 250 custom diagrams - tokenizers, attention patterns, embedding spaces, transformer blocks, RAG pipelines, multimodal architectures - all in Alammar's now-iconic clean style. The diagrams are not decoration, they are the explanation; the prose is often a caption to the figure rather than the other way around. If you have ever read 'The Illustrated Transformer' on his blog, you already know the aesthetic - this book is the same visual language extended over 400 pages. For someone like me who reads on a Boox Palma in greyscale, the diagrams still work, which is a real testament to how carefully they were designed. On a phone or tablet in colour they are genuinely a pleasure.
Same playbook as DDIA - this lives as an EPUB in my BookFusion library, on the Boox Palma when I am away from the desk and in the browser when I am at it, and I read chapters when the question matches them. Before building a new RAG-shaped feature I re-read the semantic search chapter. Before touching anything multimodal I re-read Chapter 9. When I am writing a tricky prompt for Claude Code I open the prompt engineering chapter and steal the structure. When something in a pipeline breaks, I trace it back to the relevant primitive (tokens, embeddings, attention, decoding) and ask myself what I was assuming about that primitive that turned out to be wrong. The Colab notebooks on llm-book.com are perfect for this kind of 'I just want to verify what this actually does' moment - I can run a tokenizer comparison, an embedding similarity check, or a small RAG demo in a browser tab and confirm my mental model before going back to the real code.
Two honest caveats. First, the field moves so fast that any book about it is partially out of date the day it ships - by the time I read it, several model names in the examples were already two generations behind. That is fine, because the *concepts* are the point and they have not changed, but if you are looking for the latest benchmark numbers, go elsewhere. Second, this is fundamentally a Python/PyTorch/HuggingFace book. If you live entirely in TypeScript and the Vercel AI SDK and have no intention of touching a notebook, you will still get enormous value from the conceptual chapters but you will skip half the code examples. That is what I did, and I do not regret it - the diagrams alone are worth the price.
Anyone who uses LLMs every day - whether through Claude Code, the OpenAI API, a chatbot, or as the engine behind their own product - and wants to stop treating them as magic. Junior engineers get a coherent on-ramp to the entire field in one book. Mid-level engineers building AI pipelines get a structural cure for the 'just add more prompt' anti-pattern. Senior engineers and architects get a shared vocabulary to use with their teams when reviewing AI-adjacent designs. And anyone who, like me, ships agentic workflows or RAG systems for a living gets a mental model that survives the next three model releases. If you have ever found yourself nodding along to terms like 'embedding,' 'token,' 'attention,' or 'multimodal' without being fully sure you could draw them on a whiteboard - this is the book.
Hands-On Large Language Models is the book I wish I had read a year earlier. Alammar and Grootendorst have built something genuinely rare in this corner of publishing - a beautiful, intuition-first, hands-on tour of the entire language AI stack that does not condescend, does not chase hype, and does not waste a page. It will not teach you to train GPT-5 from scratch, and it does not try to. What it will do is make every Claude Code session, every prompt you write, every RAG pipeline you architect, and every multimodal feature you ship feel less like guessing and more like engineering. In a year where 'just use AI' has become the default answer to too many questions, this book is the calm, careful, illustrated case for actually understanding what you are using. Easily one of the highest-leverage technical books I have read this year.